(本文作者为 产业家,钛媒体经授权发布)
文 | 产业家
下一代AI公司未必只诞生在拥有最大参数、最多论文和最强算力的地方,也可能诞生在真实场景最密集、产业反馈最频繁、工程迭代最快的地方。因为AI真正改变世界的方式,不是停留在屏幕里回答世界,而是进入产业现场,理解世界、模拟世界、行动于世界,并最终提升世界的运行效率。
AI似乎正在集体“逃离”纯文本,全面挺进由重力、动量、几何空间构成的真实物理世界。
1月8日,北京智源研究院发布《2026十大AI技术趋势》,将世界模型列为通向AGI的重要共识方向,并提出从Next Token Prediction(预测下一个词)向Next State Prediction(预测世界的下一个状态)的范式迁移。
随后几个月里,产业界的动作密集得几乎令人目不暇接。
首先是原本涌向具身智能的大额资金,开始对准有“世界模型”标签的企业。
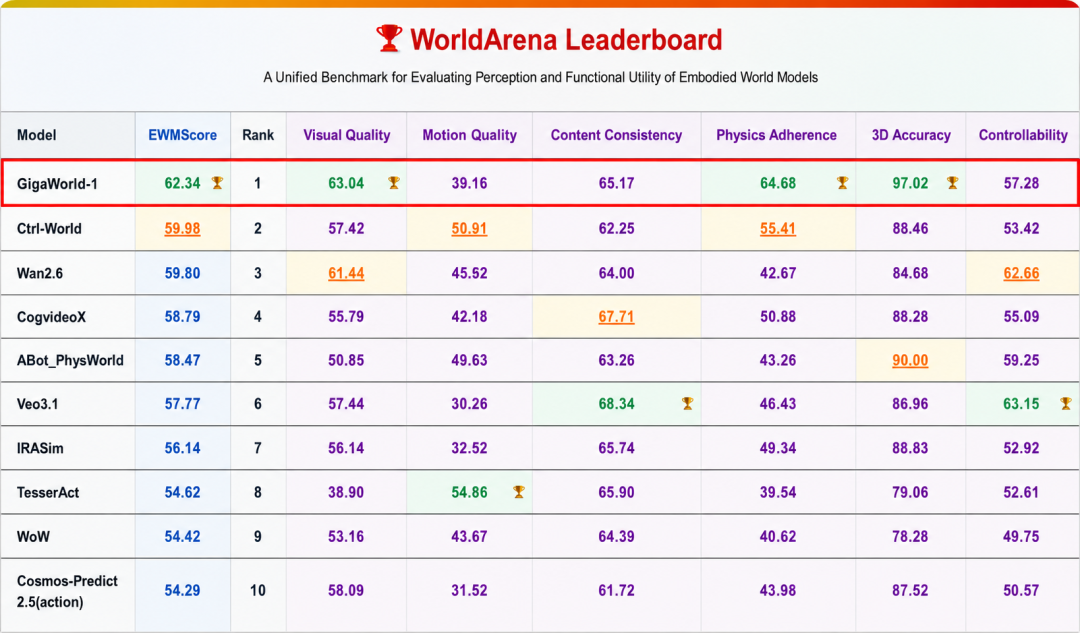
3月份,极佳视界完成约15亿元融资,同月,极佳视界的GigaWorld-1在WorldArena评测中登顶,成为全球唯一综合得分突破60分的具身世界模型,成绩超过谷歌、英伟达和阿里。从今年3月份到如今,吸金35亿,被市场称为“国内首个世界模型独角兽”;
除此之外,智平方(AI² Robotics)B 轮系列融资超 10 亿元,估值过百亿;具身基座公司千寻智能,2026 年开年三个月内完成四轮融资、吸金 45 亿元;做世界模型 Fast-WAM 的星海图,继 2 月近 10 亿元 B 轮后,4 月再拿近 20 亿元 B+ 轮;
二级市场也表现出类似的“偏爱”。
4月17日,“物理 AI”新股群核科技,作为全球首家以空间智能为核心技术底座的上市公司,上市即获得市场,上市首日大涨 144%;与此同时,生数科技两个月累计融资26亿元,投后估值超过120亿元,并传出最快于2026年启动港股IPO的消息。
值得注意的是,这俩家企业的技术路线恰是通往世界模型的路径之一。
各个领域的玩家们也蠢蠢欲动。4月16日,腾讯和阿里在同一天各自发布了一款世界模型产品。腾讯拿出的是开源的混元 3D 世界模型 2.0(HY-World 2.0),阿里端出的是主打实时交互的 HappyOyster。
车企的动作更加激进。吉利发布WAM世界行为模型,试图统一智驾、智能座舱和底盘控制;华为乾崑公开拒绝 VLA,坚持其 WA(World Action)路线,车 BU 负责人直言"VLA 看着聪明,但不是自动驾驶的真正解";Momenta 则把宝押在世界模型上。
机器人领域,英伟达Cosmos、DreamGen、DreamZero相继推出,智元发布GE-2,星海图也开始布局世界模型基础设施。
海外同样热火朝天。
图灵奖得主Yann LeCun,在执掌Meta AI多年后,于不久前选择自立门户,创立了专注于世界模型的 AMI Labs,并在2026年3月一举斩获了创纪录的10.3亿美元巨额种子轮融资。并放出话,“现有的LLM路线彻底错了,单纯靠预测文本,AI永远无法触及人类级别的智能。我们需要能理解物理现实的模型。”
李飞飞创立的World Labs于2月完成10亿美元融资,累计融资额达到12.3亿美元,估值约50亿美元,首款商业产品Marble正式上线;就在最近,OpenAI也正式宣布进入机器人赛道。
一二级市场的资金、顶尖的科学家以及跨界巨头,正以较高的密度向一个词低头,那就是世界模型。

而世界模型,又是为什么突然成为所有人的必争之地?
一、Scaling Law 放慢,行业开始寻找语言之外的答案
AI 巨头的新共识:只靠文本似乎到不了 AGI。
过去几年,大语言模型遵循着一个简单而有效的逻辑,那就是预测下一个词。这种机制带来了惊人的能力跃迁。模型不断刷新认知能力边界,也让整个行业相信,只要继续扩大参数、增加数据、堆积算力,AGI终将到来。
但2026年,一个越来越难以回避的问题出现了。那就是Scaling Law开始失灵。
以OpenAI为例,其在GPT-4.5系统卡中称GPT-4.5是“largest and most knowledgeable model yet”,且“scales pre-training further”;但在SWE-bench Verified上,GPT-4.5 post-mitigation只有38%,只比GPT-4o高2%–7%,并且比Deep Research低30%。
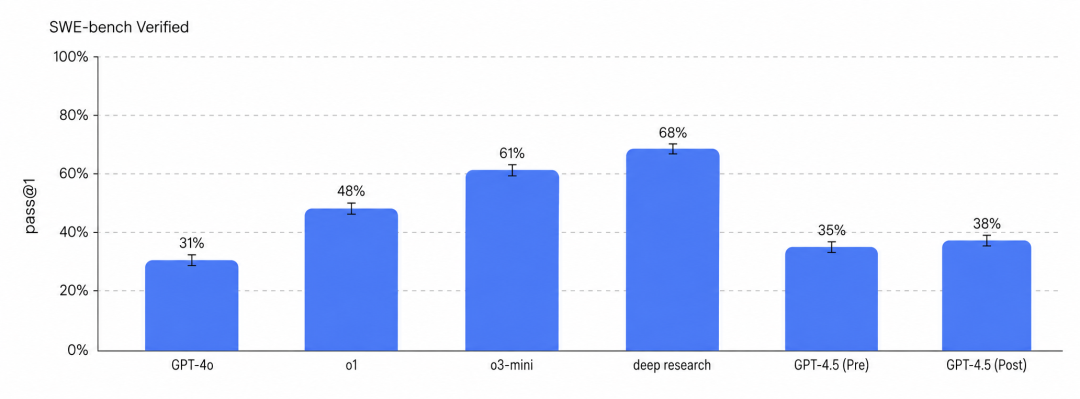
这意味着,在其模型迭代中,“更大预训练”仍有提升,但已不是最有效的能力来源。
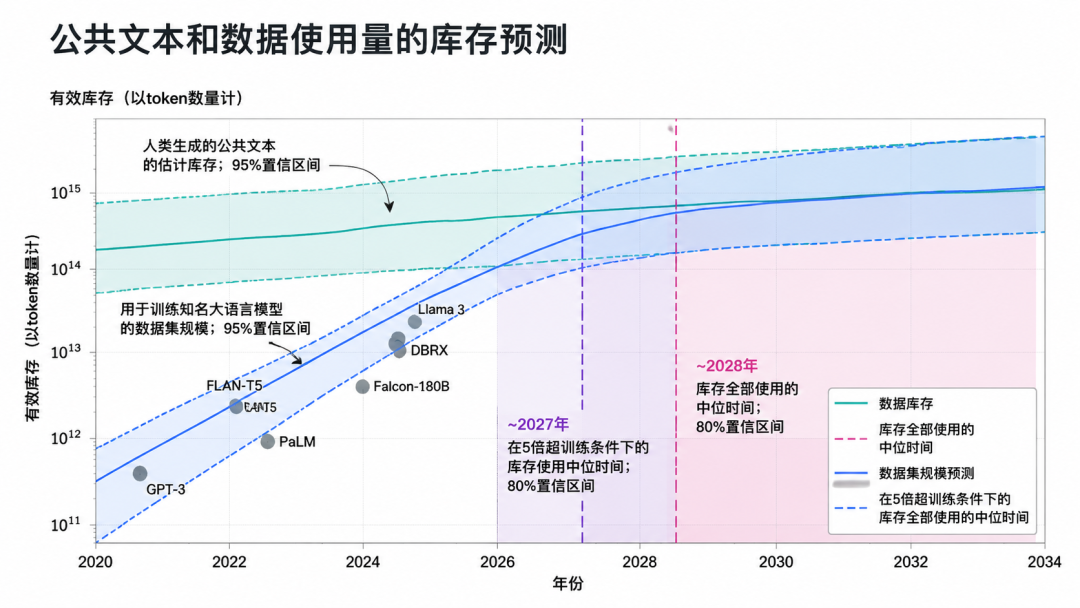
与此同时,数据墙开始出现。互联网高质量文本数据几乎被采集殆尽。Epoch AI估计,可用于AI训练的高质量、重复调整后的人类公共文本约300万亿token;若趋势继续,语言模型将在2026—2032年之间完全用尽这部分存量。
而即便拥有全世界最大的语料库,其实也无法让AI真正理解什么是重力、摩擦力、惯性和空间关系。
原因并不复杂,语料库记录的是人类如何描述世界,而不是物体如何在世界中运动。物理常识在文本中天然稀缺,因为人们通常不会反复写下“杯子会掉下去”“轮子会滚动”“湿地会打滑”这样的常识;这导致大型预训练模型在这类物理常识题上能力较低。
多模态模型也没有彻底解决这个问题。
BLINK基准显示,人类几乎一眼就能完成的深度、空间对应、多视角推理任务,GPT-4V平均只有51.26%,Gemini只有45.72%,离随机猜测并不远。
PhysBench进一步把测试扩展到摩擦、密度、张力、弹性、运动、碰撞、投掷和流体等真实物理维度;在75个视觉语言模型、10002条测试样本上,研究者发现物理理解并不会随着模型大小、训练数据量或视频帧数稳定提升。换言之,AI即使读遍互联网上关于“重力”的文字,仍可能不知道一个球为什么不能凭空消失、为什么物体不能穿墙、为什么运动必须连续。
这种局限性,最终体现为企业落地AI时最头疼的问题,那就是幻觉。
一个事实是,在金融、医疗、工业等高容错成本场景中,LLM依然无法建立稳定可靠的物理因果推理能力。这也是为什么许多企业级应用始终停留在辅助层,而无法成为核心决策系统的原因。
很明显,从“语义理解”到“物理推理”之间,始终存在一道鸿沟。而这道鸿沟已经成为AI落地产业的第一拦路虎。
可以说这是世界模型被关注的底层原因,而更为直接的原因,其实是具身智能的发展已经到了瓶颈期。
作为AI进入真实世界,通往AGI的载体,该领域在近两年可谓是香饽饽的存在,大量资金涌入,各个领域的玩家下场布局。这一局面下,市场和资本根本不会给他喘息的机会,其急需破局,寻找新的技术突破口。
而世界模型,给出了全新的解法,或者说一个新的技术叙事,让企业继续讲好这个故事。
世界模型本质是一个“可学习的物理模拟器和渲染引擎”。AI不需要依靠文字,而是通过视觉、3D运动、甚至触觉的“视觉思维链”,去预测如果采取行动A,物理环境会发生什么改变B。
可以说,LLM给AI带来了人类积攒了几千年的语言、逻辑与文明成果;而世界模型,则赋予了AI一双能够看懂时空、感受重力、理解现实的眼睛。是让AI这门技术真正转化为生产力的必经之路。
二、不同阵营的物理 AI 卡位战,抢占下一份生产力入口
如果说上一阶段的大模型竞争比的是文本的理解与生成,那么世界模型这一轮,竞争的核心已经演变为如何将AI带进一个可计算、可交互、可训练的物理世界。当前产业界对世界模型的集体押注,其实是各行各业在迫切寻找AI的下一份生产力入口。
然而必须承认,世界模型远未成熟,它既非统一的技术路线,也非短期内能替代大语言模型的万灵药,甚至连定义都没统一思想。
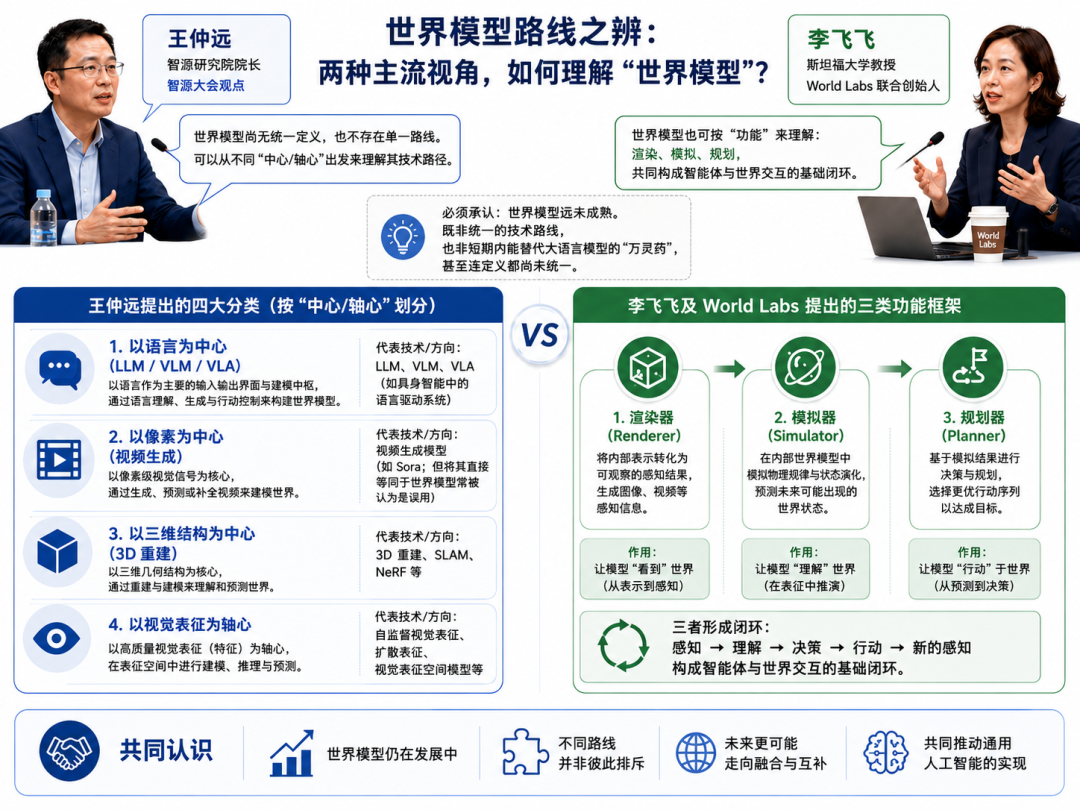
比如在最近的智源大会上,智源研究院院长王仲远提出以语言为中心(LLM/VLM/VLA)、以像素为中心(视频生成,如Sora的误用源头)、以三维结构为中心(3D重建)、以视觉表征为轴心的世界模型四大分类;
李飞飞及其World Labs团队给出的分类方式则不同,在其发布文章中,提出了渲染器、模拟器、规划器三类世界模型功能框架。
但即使如此,业内仍是处在一种由不同行业从各自优势场景出发、向“理解物理世界”靠拢的产业初试阶段。在这场由浅入深的迁徙中,不同背景的玩家正凭借各自的产业逻辑,欲想敲开世界模型的大门。
最先动起来的是视频生成派。
这一派的底气来自于手握全行业最强的视频生成引擎。生数科技、阿里的 HappyOyster、快手可灵、字节 Seedance 以及海外的 Sora、Runway 构成了第一支力量。这种趋势离不开AR-DiT 等实时交互技术的突破。过去,这类模型只能生成不可交互的“电影”,而随着 AR-DiT 等实时交互技术的突破,视频模型开始转向动作驱动的逐帧生成,让“文生视频”往“可驱动的视频世界”抬了一步。
不过,这一路线的隐患在于,它学到的是画面连贯而非物理为真,背后缺乏真实的三维结构,时间一长极易穿帮。
空间智能玩家则针锋相对,其主张“先重建,再理解”。
代表力量是李飞飞的 World Labs 和国内的群核科技。腾讯混元也凭借海量游戏数据切入这条路,将开放世界地图的建模周期从数月压到十几分钟,直接冲击游戏工业。而群核科技则作为底层的“卖水人”,从十余年家装软件中沉淀出数亿个物理正确的真实设计数据,为具身智能公司供给虚拟训练场。
真正对世界模型表现出极度需求的,是具身智能领域。
要知道,机器人最大的痛点是真实数据匮乏,而世界模型恰好能让机器人在“想象”里反复演练技能,再用少量真实数据微调。这也解释了为何大额资金开始疯狂对准有“世界模型”标签的企业。
不过,这也是路线分歧最深的一支。比如极佳视界主张在虚拟空间里通过想象学技能;智元和星海图致力于补齐仿真平台等基础设施;AMI Labs 试图绕开像素、在抽象隐空间里预测未来;而千寻智能则明确反其道而行,放弃高能耗的逐帧预测,用更少参数做轻量化预训练。目前,各条路线正走向技术融合,世界模型正在复制大语言模型的剧本,充当起具身智能的“预训练”阶段。
与机器人的长周期相比,车企与智驾厂商则把世界模型直接开上了路,成为了离钱最近的阵营。
智驾是最早握有海量真实路测数据和明确付费场景的领域。加上自动驾驶仿真已经是世界模型最成熟、且已落地的应用,用其批量合成罕见的危险场景做测试,效率比纯堆路测高出一个数量级。
站在这个角度来看,视频派从像素进、空间派从几何进、具身派从动作进、车企从场景进,本质上是不同行业根据自身场景向物理AI收敛的几个必然阶梯。短期看创意设计最快变现,中期看智能驾驶拉开差距,长期看,世界模型的终局绝非某一个单一的产品,而是未来连接数据、仿真与行动的物理AI基础设施。它是AI从数字世界走向物理世界时必须补上的关键中间层。
而当这些产业入口被逐一跑通,市场的竞争势必会向产业链深处沉降。
三、下一代 AI 公司,理解世界、模拟世界、行动于世界
世界模型之所以重要,不只是因为它代表了一条新的模型路线,更因为它正在把AI的战场从屏幕、文本和软件界面,推向汽车、机器人、工厂、仓库、建筑、城市和家庭。
大语言模型可以先在云端完成训练,再通过API、办公软件、搜索、客服、代码工具等入口扩散。它的主要战场是数字世界。但世界模型的目标不是回答问题,而是预测、生成、干预和改造物理世界。它天然要进入汽车、机器人、工厂、仓库、建筑、游戏引擎、空间设计软件和XR设备。
这意味着,世界模型的竞争不会停留在谁的模型参数更大、谁的视频更逼真、谁的榜单分数更高。真正的竞争会发生在产业链深处,比如谁拥有高质量物理数据,谁掌握仿真和评测平台,谁能连接真实设备,谁能在真实场景中形成反馈闭环。
换句话说,世界模型是AI进入物理世界时必须重建的一套基础设施。
过去的大模型产业栈相对清晰,底层是芯片和云,中间是基础模型,上层是应用和Agent。但世界模型把这条链条拉长了。未来物理AI的技术栈,可能会变成物理数据采集、数据清洗与合成、世界表示层、世界基础模型层、仿真与评测层、行动模型层、部署反馈层。
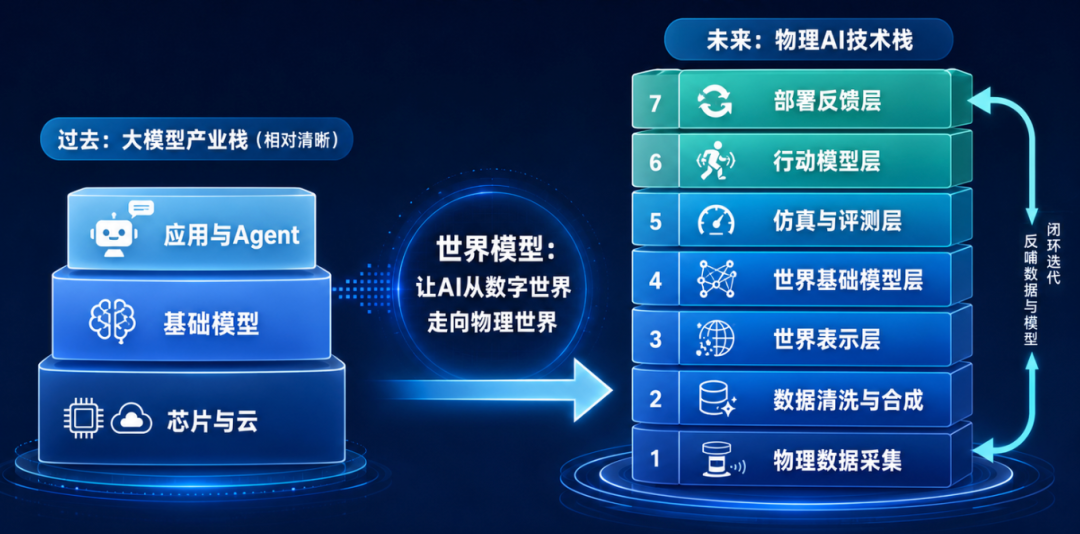
这条链条一旦形成,世界模型就不再只是“生成内容的AI”,而会成为物理AI时代的操作系统。它往下连接芯片、传感器和机器人本体,往上连接Agent、行业软件和企业业务系统;它一边接收真实世界数据,一边生成可训练、可验证、可部署的虚拟世界。它的位置,类似于大语言模型时代的基础模型,但产业嵌入程度会更深,因为它必须和物理设备、工程流程、行业标准、安全验证绑定在一起。
因此,世界模型的真正意义,其实是让AI第一次具备系统性进入物理产业的可能。
这也让中国公司在这一轮竞争中更值得关注。
在物理AI时代,竞争变量会发生变化。模型能力仍然重要,但场景密度、工程能力、供应链协同、本体制造、行业交付和客户反馈同样重要。
这恰恰是中国公司的优势区间。中国拥有全球最完整的制造业体系、最复杂的城市交通场景、增长最快的机器人产业链、庞大的新能源车市场,以及大量真实空间和工业场景。这些都是世界模型最需要的物理数据来源和落地土壤。
换句话说,世界模型的竞争不会只发生在实验室和云端,也会发生在车间、道路、仓库、门店、住宅、工地和城市基础设施中。谁能更快把模型接入这些场景,谁能更快获得真实反馈,谁就有可能建立更强的工程闭环和数据飞轮。
这意味着,下一代AI公司未必只诞生在拥有最大参数、最多论文和最强算力的地方,也可能诞生在真实场景最密集、产业反馈最频繁、工程迭代最快的地方。因为AI真正改变世界的方式,不是停留在屏幕里回答世界,而是进入产业现场,理解世界、模拟世界、行动于世界,并最终提升世界的运行效率。
更多精彩内容,关注钛媒体微信号(ID:taimeiti),或者下载钛媒体App
本文为本站原创内容,如需转载请注明出处。
本文永久地址:https://m.ace6239.store/article/14400.html
文章观点仅供学习交流参考。